
X-Chem’s DNA-encoded library (DEL) technology is deployed for and by clients around the world as an important method of small molecule discovery. Biotech and pharma companies recognize the exponential advantages of screening billions of compounds with astonishing speed and efficiency.
Our libraries are maximally diverse and designed to generate hit compounds that jump-start medicinal chemistry programs. DELability, DELflex, DELcore and DELvalent offer target-based screening solutions and with our DELenable option, we even deliver support to help clients build internal DEL capabilities using our extensive experience.

X-Chem’s versatile DEL screening is proven in projects spanning numerous target classes. Our robust process has been highly successful against targets considered difficult or even intractable, such as:
- Protein-protein interactions
- Ubiquitin ligases
- Epigenetic targets
- G protein-coupled receptors
- Bacterial enzymes
Our platform, libraries and screening strategies are designed to generate compound classes that can address any target and modality:
- Lead-like compounds
- Drug-like compounds
- Macrocycles
- Peptides
- Covalent inhibitors
- Protein degraders
- Allosteric inhibitors
HOW DEL-DRIVEN DRUG DISCOVERY WORKS:
Combinatorial Chemistry, DNA Tagging and High Affinity-Based Screening
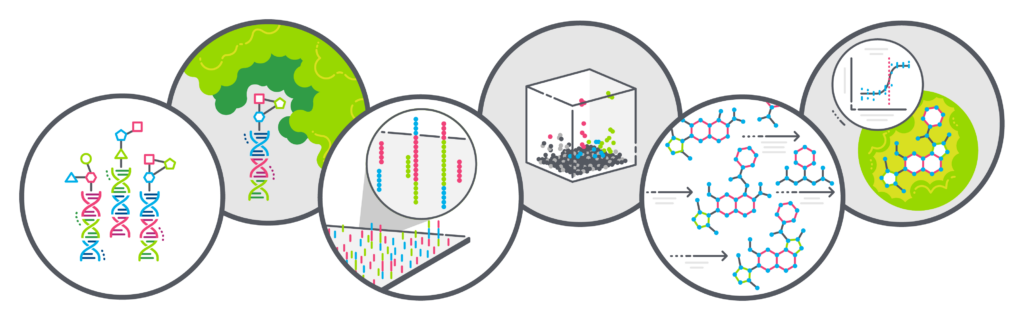
| 1 |
The X-Chem drug discovery engine is based on a compound library generated by iterative combinatorial synthesis. In the DEL process, each molecule in the library is tethered to a distinct DNA tag or “bar code” that records its synthetic history. |
| 2 |
Billions of small molecules are screened as a mixture in a single vessel against a target of interest. Conducting multiple screening experiments in parallel provides informative and actionable output. |
| 3 |
DNA amplification and sequencing methods are then used to identify the molecules that have an affinity for your target. |
| 4 |
Proprietary bioinformatics tools allow the translation of DNA sequence data into chemical structure, and the analysis of the enrichment and structural characteristics of the resulting ligands. |
| 5 |
Based on the synthetic history encoded in the DNA sequence information, promising molecules are then synthesized without the DNA tag attached. |
| 6 |
These de-tagged hits are then retested in biological assays to confirm that they exhibit the desired activity. The structure-activity relationships observed in the screening help accelerate hit-to-lead medicinal chemistry. |
Whether you are a DEL practitioner or an investigator looking for equity against a novel target, we will help you leverage our platform, technology and expertise in the best way possible.